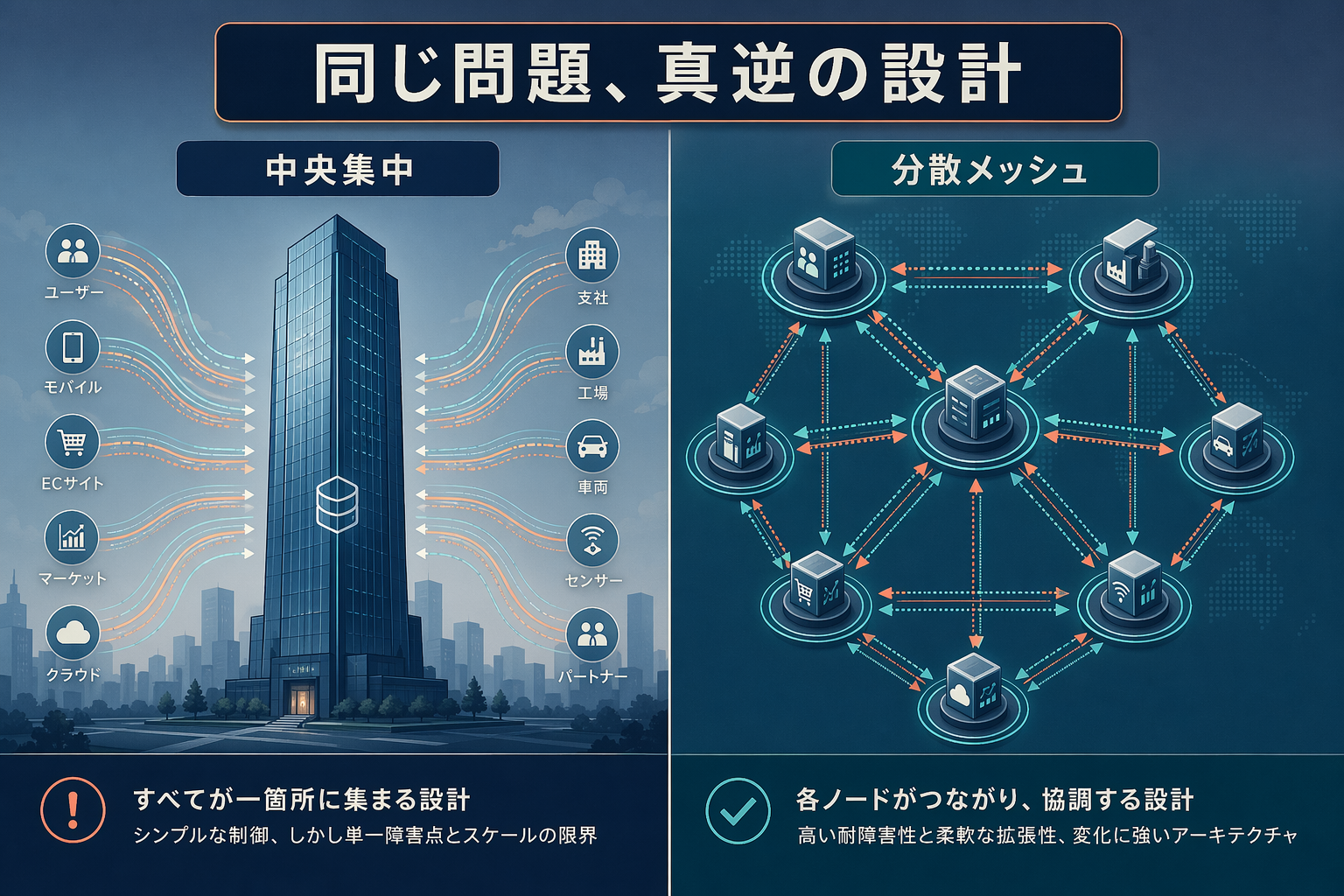
IPA Open Data Spaces と Palantir Foundry Ontology は真逆の設計思想で同じ問題を解いている
2026 年 4 月 1 日、IPA が「Open Data Spaces(ODS)」の成果物一式を公開しました。設計思想の白書(Why Open Dataspaces)、参照アーキテクチャ(ODS-RAM V2)、プロトコル仕様(ODP)、オープンソース実装群、そして事業者・技術者向けガイドブックまで、概念から実装までを一気に並べた発表です。
一方で、エンタープライズでは Palantir Foundry の Ontology が「AI が業務判断に踏み込むためのデータ基盤」として広まりつつあります。両者はどちらも Ontology(オントロジー:業務概念と関係性をコンピュータが扱える形で記述したもの) を中心に据えますが、基本設計は正反対です。Ontology そのものの位置づけや AI Ready なデータ基盤の文脈は AI Readyなデータ基盤とオントロジー実装入門 で整理しているので、先に一読しておくと本記事の対比がくっきり見えるはずです。
この記事では、ODS と Palantir Foundry Ontology を 「集中 vs 分散」 と 「静的 Ontology vs Dynamic Ontology」 の 2 軸で比較し、データ基盤選定にあたる データアナリスト・データエンジニア・アーキテクト が、どちらのパラダイムに寄せるべきか判断できる状態を目指します。
前提: ODS と Palantir Foundry Ontology は何を目指しているか
Open Data Spaces(ODS) は、IPA が主導し NEDO・東大・DSA・RRI が参画する官民学連携プロジェクトで、「国や組織ごとの多様性を尊重する、オープンでスケーラブルな分散データマネジメント」を技術コンセプトに掲げます。Dehghani のデータメッシュ(組織内のドメイン分散)を 組織境界を越えた領域に拡張 した点が、従来のデータスペース系仕様との差分です。
Palantir Foundry Ontology は、Palantir が提供する商用プラットフォーム Foundry 上の Ontology レイヤーです。社内のデータセット・モデル・外部データを統合し、Object(モノ)/Link(関係)/Action(操作) の 3 軸で業務の意思決定を支える「エンタープライズの運用基盤」として位置づけられます。
どちらも解きたいのは同じ問題、「組織が持つ分散したデータを、AI に業務判断をさせられるレベルの意味づきで繋ぐ」 です。違うのは どこに意味を置くか と 誰が統合の責任を負うか の 2 点です。
軸 1: アーキテクチャは「Push and Ingest」か「Serving and Pull」か
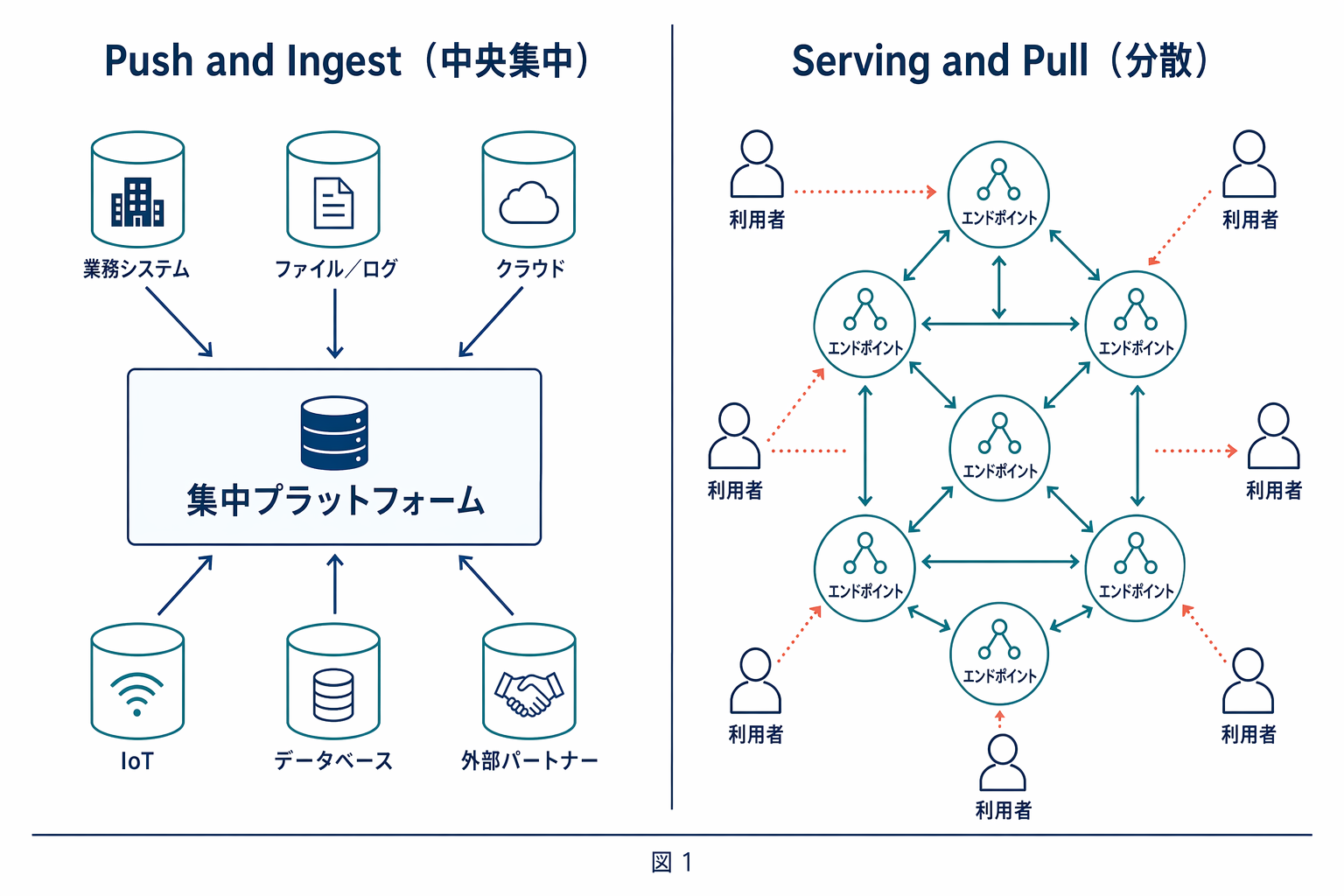
Palantir Foundry は古典的な Push and Ingest パラダイムの洗練形です。各ソース(基幹系、SaaS、IoT)から Foundry 側の Object Data Funnel がデータを吸い上げ、Ontology Metadata Service(OMS) が定義した型に沿ってオブジェクト DB へ格納します。統合の責任は中央のプラットフォームに集中し、読み手(Object Explorer、Workshop アプリ、AIP の AI エージェント)はすべて同一の Foundry 上から Ontology にアクセスします。
ODS は真逆の Serving and Pull 型です。ドメインオーナー(業務部門・サプライヤー)は、自分の持ち場のデータを Ontology Endpoint(意味を返す)と Data Endpoint(データを返す) の 2 つのインターフェースとして公開し、IRI(国際化リソース識別子:URL を任意文字でグローバル一意に拡張したもの) で識別します。消費者は必要な Ontology を Ontology Query で引いてから、該当する Data を Data Query で引きます。統合は中央で起きず、エンドポイントを提供する側と引く側の契約 として分散します。
このアーキテクチャの差は、そのまま ベンダーロックイン の存在に直結します。Foundry は統合の便利さと引き換えに中央プラットフォームへの依存を受け入れる設計で、ODS は設計思想として明示的にベンダーロックインと制度的ロックインの回避を掲げています。
軸 2: Ontology は「先に定義する」か「動的に生やす」か
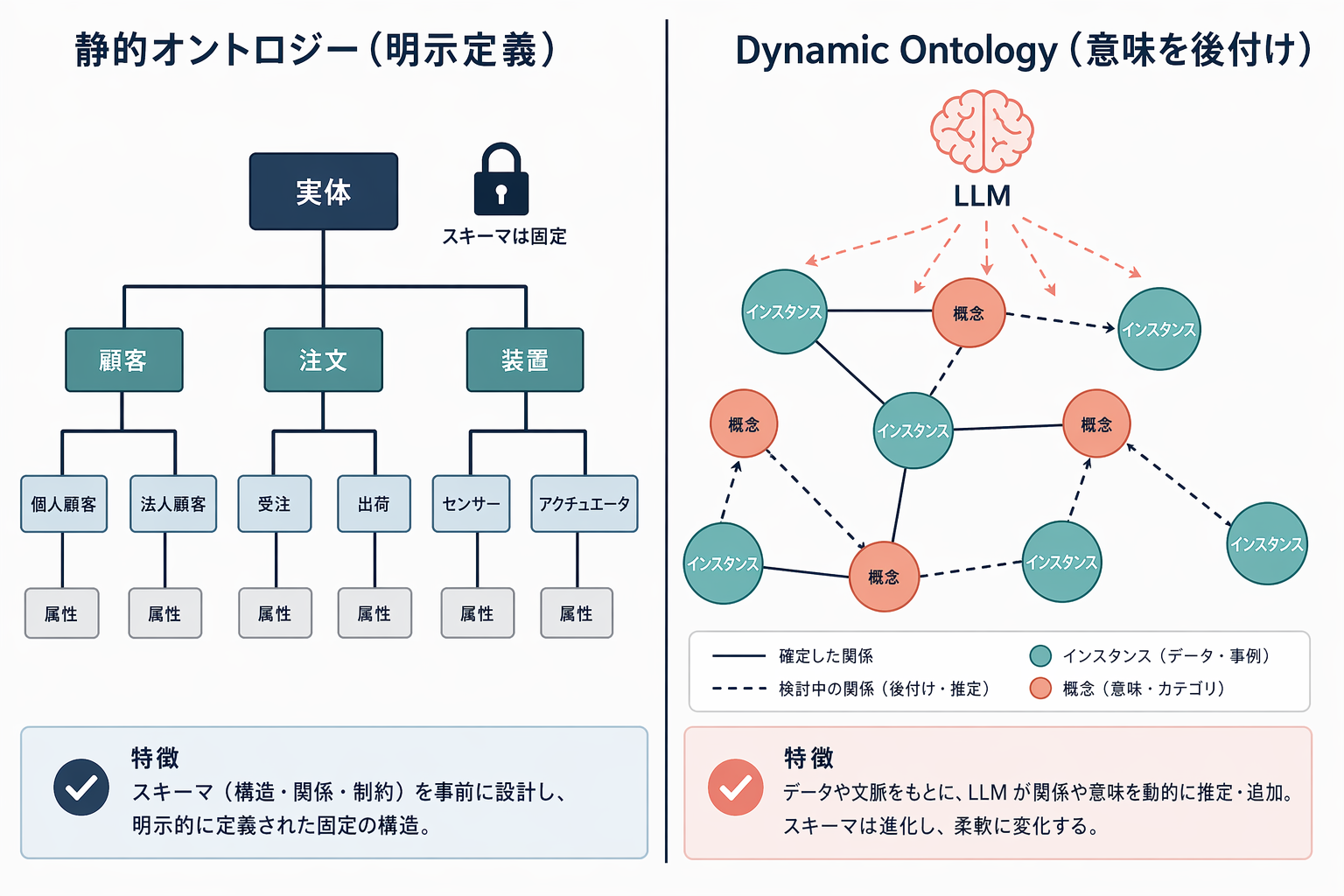
Palantir の Ontology は 静的・明示定義型 です。Object Type(顧客・装置・注文)と Link Type(顧客が注文する、装置が顧客に紐づく)、Action Type(注文ステータスを進める)を人間が先に設計し、データをそこに流し込みます。強みは AI エージェントに渡すときの意味が揺るがない ことで、AIP(Palantir の AI プラットフォーム)が Ontology を介して業務操作できるのはこの明示性が支えています。
対して ODS は 「先にインスタンス(データ)があり、そこに意味を後から付与する」 を方針に掲げ、Dynamic Ontology を採用します。具体的には LLM が Ontological Gap(型定義と実データの意味的な食い違い)を埋める ことで、スキーマを先に揃えられないほど多様なドメインでも、推測(Guess)から知識(Knowledge)へ ゆっくり収束させていく発想です。
ここに 「データ枯渇元年」 と呼ばれる 2026 年の文脈が効いてきます。IPA の白書は、世界で生まれるリアルデータのうち 約 16 ZB がインターネット非公開の「ダークデータ」 であり、このダークデータを活用するには事前スキーマ統一が現実的ではない、という論点を置いています。Dynamic Ontology は、この 「意味合わせを前提条件にしない」 という実務制約に合わせた設計判断です。
軸 3: AI エージェント時代の位置づけ
Palantir のアプローチは「既存の業務資産を Ontology 化して、AI エージェントが安全に操作できる面にする」というものです。AI が「注文を承認する」という Action を実行できるのは、Action Type が事前に定義され、権限と副作用が厳密にモデル化されているからです。したがって AI が業務トランザクションに踏み込む 用途ではいまのところ圧倒的に強い選択肢です。
ODS は明示的に Agentic AI ネイティブ時代のアーキテクチャ を標榜しています。AI エージェントが組織・国境を跨いで Ontology Endpoint を自律的に引き、Dynamic Ontology で意味を補完しながら業務を進める世界観です。現時点では参照実装と仕様公開の段階ですが、複数企業・複数国にまたがるサプライチェーン・カーボンニュートラル・資源循環 のように、中央プラットフォームに全データを集める選択肢が取れない領域では本命になります。
選定軸: どちらをいつ選ぶか
この 2 つは同じ市場の直接競合ではなく、前提とする組織境界の違い で住み分けます。筆者が現場で使うときの判断軸を整理すると次のようになります。
| 判断軸 | Palantir Foundry 有利 | Open Data Spaces 有利 |
|---|---|---|
| 立ち上げ速度 | 短期間で Ontology と UI を組める | 仕様準拠のエンドポイント実装が必要 |
| ベンダー独立性 | 中央プラットフォームに依存 | オープン仕様・OSS 参照実装、ロックイン回避 |
| データ境界 | 単一組織内、または密なグループ企業 | 組織・国境を越えるサプライチェーン型 |
| Ontology 設計コスト | 事前に明示設計が必要(人手) | Dynamic Ontology で段階的に収束 |
| AI が業務を実行する前提 | Action Type で厳密に定義済み | 仕様策定途上、標準化の勝負 |
| 運用コスト | ライセンス+運用コストが中央に集中 | 各ドメインが自分の Endpoint を保守 |
単一企業内での AI による業務オペレーション高度化が目的なら Palantir が合います。サプライチェーンやマルチステークホルダーのデータ連携、あるいは 「中央に集めない」が要件に含まれる プロジェクトなら ODS の方向に寄せるのが筋です。
まとめ
ODS と Palantir Foundry Ontology は、同じ「AI に業務判断をさせられる Ontology 付きデータ基盤」 という問題に、集中 vs 分散・静的 vs Dynamic という反対側の入り口から入っています。どちらが正しいかではなく、自分の組織が越えたい境界がどこまでか で選ぶレイヤーの問題です。
ODS は 2026 年 4 月 1 日公開と立ち上がったばかりで、仕様書・参照実装ともに読み込みどころが多い段階です。エンタープライズのデータ基盤に関わる人は、Palantir を現実解として抑えつつ、ODS の設計思想白書を読んで 自社のデータが「中央に集められる前提」で組まれているか を一度棚卸ししておくと、3〜5 年後の選択肢が大きく増えます。
出典 Issue
- IPA Open Data Spaces と Palantir Foundry Ontology の比較記事を執筆する — source repo:
analytics-note/analytics_note
参考リンク
- IPA プレス発表(2026-04-01): Open Data Spaces(ODS)の成果物を公開
- IPA: Why Open Dataspaces: 設計思想とアーキテクチャパラダイム
- IPA: Open Data Spaces(プロジェクトトップ)
- OSS 参照実装: github.com/open-dataspaces
- Palantir: Foundry Ontology Overview
- Palantir: Ontology architecture