目次
- なぜ政府統計データが面白いか
- DuckDB で e-Stat API を直接クエリする(探索フェーズ)
- アーキテクチャ設計: L0〜L4 の5層
- Python e-Stat クライアントの設計
- GCS raw アーカイブと BigQuery bronze テーブル
- dbt silver モデルの設計
- dbt mart モデル(都道府県別人口推移)
- Cloud Run ingest エントリポイント
- 運用上の注意点
- まとめと今後の展開
なぜ政府統計データが面白いか
政府統計データは、データ分析プロダクトに外部信号を加える最もコスパの高いリソースのひとつです。 無料・商用利用可・高品質という三拍子が揃った e-Stat(政府統計の総合窓口)を活用することで、自社データだけでは見えなかったマクロトレンドとの相関を掘り起こせます。
e-Stat は総務省統計局が運営するポータルサイトで、e-Stat API を通じてプログラムからデータを取得できます。e-Stat は、国勢調査・住民基本台帳・産業統計など数千のデータセットを REST API 経由で提供しています。APIキーの取得は無料で、商用利用も許可されており、レスポンスは JSON または XML で受け取れます。利用規約(CC BY 4.0 相当)に従う限り、SaaS プロダクトの機能に組み込むことも問題ありません。
具体的にどんな活用シーンがあるか。例えば、EC サイトの売上モデルに都道府県別人口・年齢構成を説明変数として加える、採用プロダクトに地域別就業者数トレンドを重ねる、不動産分析に人口移動統計を紐付けるといったケースが考えられます。こうした外部信号は、自社の行動ログだけでは再現できない文脈を与えてくれます。
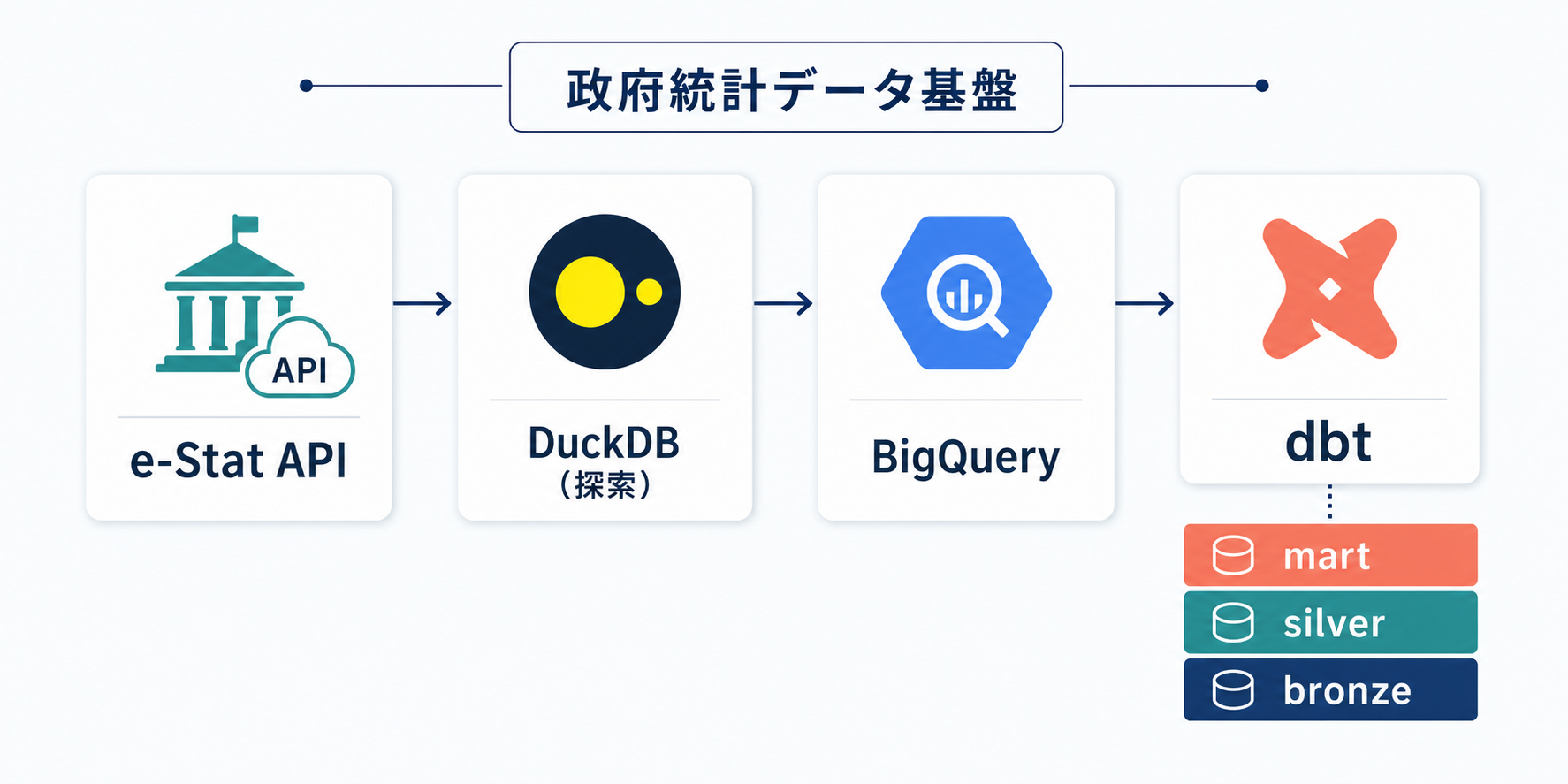
本記事では、e-Stat API をデータ基盤に取り込む具体的なアーキテクチャとして DuckDB による即席探索 → Python クライアント → GCS/BigQuery bronze → dbt silver/mart という流れを設計から実装まで解説します。実際に手を動かせるコードを多く含めていますので、そのまま試してみてください。
DuckDB で e-Stat API を直接クエリする(探索フェーズ)
新しいデータソースを本番パイプラインに組み込む前に、まず DuckDB でその場探索するのが最速アプローチです。 DuckDB は read_text() 関数で HTTP エンドポイントを直接クエリでき、JSON の解析まで SQL 一本で完結します。ローカルに追加のミドルウェアをインストールする必要はありません。
e-Stat API の概要
e-Stat REST API が提供する主要エンドポイントは以下の3つです。本記事ではすべてのエンドポイントを扱います。
| エンドポイント | 用途 | 主なパラメータ |
|---|---|---|
getStatsList | 統計表の一覧を取得 | searchWord, limit, statsCode |
getMetaInfo | 統計表のメタ情報(分類・属性)を取得 | statsDataId |
getStatsData | 統計数値を取得 | statsDataId, cdArea, cdTime |
API キーは e-Stat アカウント登録 から無料で発行できます。発行後、appId パラメータとして各リクエストに付与します。
DuckDB で統計表一覧をクエリする
DuckDB CLI(またはJupyterのDuckDB接続)を起動し、以下を実行します。ESTAT_APP_ID にはご自身のアプリIDをセットしてください。
-- アプリIDをセッション変数に格納
SET VARIABLE estat_app_id = 'YOUR_APP_ID_HERE';
-- e-Stat API getStatsList を直接クエリ(検索ワード「人口」)
SELECT
json_extract(value, '$.@id')::VARCHAR AS stats_data_id,
json_extract(value, '$.STAT_NAME."$"')::VARCHAR AS stat_name,
json_extract(value, '$.TITLE."$"')::VARCHAR AS title,
json_extract(value, '$.SURVEY_DATE')::VARCHAR AS survey_date,
json_extract(value, '$.OPEN_DATE')::VARCHAR AS open_date
FROM (
SELECT unnest(
json_extract(
read_text(
'https://api.e-stat.go.jp/rest/3.0/app/json/getStatsList?appId='
|| getvariable('estat_app_id')
|| '&searchWord=人口&limit=100'
)::JSON,
'$.GET_STATS_LIST.DATALIST_INF.TABLE_INF'
)
) AS value
)
LIMIT 20;このクエリは e-Stat API にリクエストを送り、返ってきた JSON をその場で展開して表形式に変換します。結果から興味深い stats_data_id を見つけたら、次は getMetaInfo でどんな分類軸があるか確認します。
-- 特定統計表のメタ情報を確認
SELECT
json_extract(value, '$.@code')::VARCHAR AS class_code,
json_extract(value, '$.@name')::VARCHAR AS class_name,
json_extract(value, '$.@description')::VARCHAR AS description
FROM (
SELECT unnest(
json_extract(
read_text(
'https://api.e-stat.go.jp/rest/3.0/app/json/getMetaInfo?appId='
|| getvariable('estat_app_id')
|| '&statsDataId=0003412313' -- 国勢調査の例
)::JSON,
'$.GET_META_INFO.METADATA_INF.CLASS_INF.CLASS_OBJ'
)
) AS value
);実際のデータ値を取得する
統計表の構造が把握できたら getStatsData で数値を取得します。
-- 都道府県別・年次の人口データを取得
SELECT
json_extract(value, '$.@area')::VARCHAR AS area_code,
json_extract(value, '$.@time')::VARCHAR AS time_code,
json_extract(value, '$.@cat01')::VARCHAR AS category_code,
json_extract(value, '$."$"')::DOUBLE AS stat_value
FROM (
SELECT unnest(
json_extract(
read_text(
'https://api.e-stat.go.jp/rest/3.0/app/json/getStatsData?appId='
|| getvariable('estat_app_id')
|| '&statsDataId=0003412313'
|| '&metaGetFlg=N'
|| '&cntGetFlg=N'
|| '&limit=1000'
)::JSON,
'$.GET_STATS_DATA.STATISTICAL_DATA.DATA_INF.VALUE'
)
) AS value
)
LIMIT 50;DuckDB 探索のメリットは、仮説検証が SQL 一本で完結する点です。「この統計表は使えそうか」「どのフィールドが必要か」を確認するだけなら、Python スクリプトをゼロから書く必要はありません。探索で見当を付けてから、本番パイプラインの設計に進みましょう。
アーキテクチャ設計: L0〜L4 の5層
データ基盤全体を5つの論理層に分けることで、探索・収集・変換・提供の責務を分離します。 なぜ5層なのか。データパイプラインで最もコストがかかるのは「やり直し」です。生データを直接加工してしまうと、変換ロジックを変えたいときに API からの再取得が必要になります。層を分けておけば、特定の層だけ差し替えても全体への影響を局所化でき、やり直しのコストを最小化できます。
L0: Source
e-Stat API(getStatsList / getMetaInfo / getStatsData)
↓
L1: Raw / Bronze
GCS raw archive(JSON ファイル)
BigQuery bronze テーブル(生 JSON 文字列)
↓
L2: Silver
dbt で型変換・正規化
dim_estat_stat / dim_estat_area / fact_estat_value
↓
L3: Mart
dbt で集計・結合
mart_population_prefecture_year 等
↓
L4: Application
BI ツール(Looker Studio 等)
プロダクト外部信号 API各層の設計方針
| 層 | ストレージ | 変換の種類 | 変更頻度 |
|---|---|---|---|
| L0 Source | e-Stat API | なし | API 仕様変更時 |
| L1 Bronze | GCS + BigQuery | なし(生データ保存) | 収集バッチ更新時 |
| L2 Silver | BigQuery | 型変換・NULL 処理・正規化 | スキーマ変更時 |
| L3 Mart | BigQuery | 集計・JOIN・ビジネスロジック | 要件変更時 |
| L4 Application | 各ツール固有 | 表示ロジックのみ | 頻繁 |
Bronze に生データをそのまま保存しておく設計(いわゆる「生ログ永久保存」)は重要です。e-Stat の API レスポンス仕様が変わっても、Bronze の JSON から Silver を再生成できます。dbt の --full-refresh と組み合わせることで、過去データを含めた再変換が可能になります。
リポジトリ境界の設計
Hub リポジトリ(analytics_note)には docs/ADR のみを置き、実装は Lab リポジトリ(external-signal)に分離します。この境界を守ることで、Hub は方針・ドキュメント管理に専念でき、Lab は実験的な変更を安全に進められます。
analytics_note/ # Hub リポジトリ
docs/adr/005-estat-external-signal.md
docs/external-data-sources.md
external-signal/ # Lab リポジトリ
src/
collectors/estat/ # e-Stat APIクライアント
loaders/bigquery/ # BigQuery ローダー
dbt/
models/
bronze/ # Bronze ビュー(ソース定義)
silver/ # Silver テーブル
mart/ # Mart テーブル
infra/
terraform/ # GCS バケット・BQ データセット
tests/Python e-Stat クライアントの設計
型安全・リトライ・ロギングを備えた e-Stat クライアントを設計することで、本番パイプラインの信頼性を確保します。 探索フェーズの DuckDB クエリは便利ですが、定期実行する本番バッチには Python クライアントが適しています。
クライアント実装
# src/collectors/estat/client.py
from __future__ import annotations
import os
import time
import logging
from typing import Any
import requests
logger = logging.getLogger(__name__)
class EStatAPIError(Exception):
"""e-Stat API 固有のエラー"""
pass
class EStatClient:
"""e-Stat REST API v3.0 クライアント
環境変数 ESTAT_APP_ID からアプリIDを読み込む。
リトライは指数バックオフで最大3回試行する。
"""
BASE_URL = "https://api.e-stat.go.jp/rest/3.0/app/json"
MAX_RETRIES = 3
RATE_LIMIT_SLEEP = 1.0 # e-Stat 推奨: 1秒に1リクエスト
def __init__(self) -> None:
self.app_id = os.environ["ESTAT_APP_ID"]
self.session = requests.Session()
self.session.headers.update({"Accept": "application/json"})
def _get(self, endpoint: str, params: dict[str, Any]) -> dict:
"""共通 GET リクエスト(リトライ付き)"""
url = f"{self.BASE_URL}/{endpoint}"
params = {"appId": self.app_id, **params}
for attempt in range(self.MAX_RETRIES):
try:
resp = self.session.get(url, params=params, timeout=30)
resp.raise_for_status()
data = resp.json()
# e-Stat 独自のエラーレスポンスを検出
status = data.get("GET_STATS_LIST", {}).get("RESULT", {}).get("STATUS")
if status and status != 0:
msg = data.get("GET_STATS_LIST", {}).get("RESULT", {}).get("ERROR_MSG", "")
raise EStatAPIError(f"API error status={status}: {msg}")
return data
except (requests.RequestException, EStatAPIError) as exc:
if attempt == self.MAX_RETRIES - 1:
logger.error(
"Request failed after %d attempts: url=%s params=%s error=%s",
self.MAX_RETRIES, url, params, exc,
)
raise
wait = 2 ** attempt
logger.warning("Retrying in %ds (attempt %d): %s", wait, attempt + 1, exc)
time.sleep(wait)
raise RuntimeError("Unreachable") # mypy 向け
def get_stats_list(
self,
search_word: str | None = None,
stats_code: str | None = None,
limit: int = 100,
start_position: int = 1,
) -> dict:
"""統計表一覧を取得する(getStatsList)"""
params: dict[str, Any] = {"limit": limit, "startPosition": start_position}
if search_word:
params["searchWord"] = search_word
if stats_code:
params["statsCode"] = stats_code
result = self._get("getStatsList", params)
time.sleep(self.RATE_LIMIT_SLEEP)
return result
def get_meta_info(self, stats_data_id: str) -> dict:
"""統計表のメタ情報を取得する(getMetaInfo)"""
result = self._get("getMetaInfo", {"statsDataId": stats_data_id})
time.sleep(self.RATE_LIMIT_SLEEP)
return result
def get_stats_data(
self,
stats_data_id: str,
cd_area: str | None = None,
cd_time: str | None = None,
limit: int = 10000,
) -> dict:
"""統計データを取得する(getStatsData)"""
params: dict[str, Any] = {
"statsDataId": stats_data_id,
"metaGetFlg": "N",
"cntGetFlg": "N",
"limit": limit,
}
if cd_area:
params["cdArea"] = cd_area
if cd_time:
params["cdTime"] = cd_time
result = self._get("getStatsData", params)
time.sleep(self.RATE_LIMIT_SLEEP)
return result設計上のポイント
指数バックオフの実装意図について説明します。e-Stat API は公共サービスであり、特定の時間帯に高負荷になることがあります。2 ** attempt の待機時間(1秒 → 2秒 → 4秒)により、一時的なエラーから自動回復しつつサーバーへの負荷を抑えられます。
RATE_LIMIT_SLEEP = 1.0 は e-Stat の利用ガイドラインに沿った設定です。大量の統計表を収集する際はこの値を守り、不必要な高速アクセスは避けてください。APIの制限に引っかかると全リクエストが503を返すようになるため、後続の全バッチに影響が及びます。
GCS raw アーカイブと BigQuery bronze テーブル
生データを GCS にアーカイブしてから BigQuery に取り込む2段階設計は、データ損失リスクを最小化するベストプラクティスです。 GCS が「真実の源泉」となるため、BigQuery 側に不具合が起きても再ロードできます。
GCS パーティション設計
gs://<project>-estat-raw/
estat/
raw/
2026/
04/
08/
0003412313.json # stats_data_id がファイル名
0003412314.json
...
2026/
04/
09/
...日付でパーティションすることで、特定日のデータを再収集した際に上書きするだけで済みます。stats_data_id をファイル名にすることで、BigQuery からの逆引きも容易になります。
BigQuery データセットとテーブル構成
-- bronze データセット作成(Terraform 管理推奨)
CREATE SCHEMA IF NOT EXISTS `{project}.bronze`
OPTIONS (
location = 'asia-northeast1',
description = 'e-Stat raw JSON archive'
);
-- bronze.estat_stats_data テーブル
CREATE TABLE IF NOT EXISTS `{project}.bronze.estat_stats_data`
(
ingested_at TIMESTAMP NOT NULL,
stats_data_id STRING NOT NULL,
raw_json STRING NOT NULL -- JSON 文字列をそのまま保存
)
PARTITION BY DATE(ingested_at)
CLUSTER BY stats_data_id
OPTIONS (
partition_expiration_days = NULL, -- 無期限保持
description = 'e-Stat getStatsData の生JSONアーカイブ'
);
-- bronze.estat_stats_list テーブル(統計表一覧)
CREATE TABLE IF NOT EXISTS `{project}.bronze.estat_stats_list`
(
ingested_at TIMESTAMP NOT NULL,
search_word STRING,
raw_json STRING NOT NULL
)
PARTITION BY DATE(ingested_at)
OPTIONS (
description = 'e-Stat getStatsList の生JSONアーカイブ'
);BigQuery ローダー実装
# src/loaders/bigquery.py
from __future__ import annotations
import json
import logging
from datetime import datetime, timezone
from google.cloud import bigquery
logger = logging.getLogger(__name__)
class BQLoader:
"""BigQuery へのデータロードを担当するクラス"""
def __init__(self, project: str | None = None, dataset: str = "bronze") -> None:
self.client = bigquery.Client(project=project)
self.dataset = dataset
def insert_raw(
self,
table_name: str,
data: dict,
extra_fields: dict | None = None,
) -> int:
"""JSON データを bronze テーブルにストリーミング挿入する"""
table_ref = f"{self.client.project}.{self.dataset}.{table_name}"
row = {
"ingested_at": datetime.now(tz=timezone.utc).isoformat(),
"raw_json": json.dumps(data, ensure_ascii=False),
**(extra_fields or {}),
}
errors = self.client.insert_rows_json(table_ref, [row])
if errors:
logger.error("BigQuery insert errors: %s", errors)
raise RuntimeError(f"BigQuery insert failed: {errors}")
logger.info("Inserted 1 row to %s", table_ref)
return 1dbt silver モデルの設計
Silver 層の責務は「型変換・NULL 処理・正規化」に絞り込み、ビジネスロジックを持ち込まないことが重要です。 Bronze の生 JSON から構造化テーブルを生成し、Mart 層が安心して使えるデータを提供します。
dbt プロジェクト構成
dbt/
dbt_project.yml
profiles.yml # .gitignore 対象
models/
sources.yml # bronze テーブルのソース定義
silver/
dim_estat_stat.sql
dim_estat_area.sql
fact_estat_value.sql
schema.yml
mart/
mart_population_prefecture_year.sql
schema.yml
tests/
macros/sources.yml の定義
# dbt/models/sources.yml
version: 2
sources:
- name: bronze
database: "{{ env_var('DBT_PROJECT_ID') }}"
schema: bronze
tables:
- name: estat_stats_data
description: "e-Stat getStatsData の生JSONアーカイブ"
columns:
- name: ingested_at
description: "取り込み日時(UTC)"
- name: stats_data_id
description: "e-Stat 統計表ID"
- name: raw_json
description: "APIレスポンスの生JSON文字列"
- name: estat_stats_list
description: "e-Stat getStatsList の生JSONアーカイブ"dim_estat_stat.sql(統計表マスタ)
-- dbt/models/silver/dim_estat_stat.sql
{{ config(
materialized='table',
partition_by={
'field': 'ingested_date',
'data_type': 'date'
},
cluster_by=['stats_data_id']
) }}
WITH source AS (
SELECT
stats_data_id,
raw_json,
ingested_at,
DATE(ingested_at) AS ingested_date,
-- 最新取り込みのみ残す
ROW_NUMBER() OVER (
PARTITION BY stats_data_id
ORDER BY ingested_at DESC
) AS rn
FROM {{ source('bronze', 'estat_stats_data') }}
WHERE stats_data_id IS NOT NULL
),
parsed AS (
SELECT
stats_data_id,
JSON_VALUE(raw_json, '$.GET_STATS_DATA.STATISTICAL_DATA.TABLE_INF.@id')
AS stats_data_id_from_json,
JSON_VALUE(raw_json, '$.GET_STATS_DATA.STATISTICAL_DATA.TABLE_INF.STAT_NAME."$"')
AS stat_name,
JSON_VALUE(raw_json, '$.GET_STATS_DATA.STATISTICAL_DATA.TABLE_INF.TITLE."$"')
AS title,
JSON_VALUE(raw_json, '$.GET_STATS_DATA.STATISTICAL_DATA.TABLE_INF.SURVEY_DATE')
AS survey_date,
JSON_VALUE(raw_json, '$.GET_STATS_DATA.STATISTICAL_DATA.TABLE_INF.OPEN_DATE')
AS open_date,
ingested_at,
ingested_date
FROM source
WHERE rn = 1
)
SELECT *
FROM parsed
WHERE stat_name IS NOT NULLfact_estat_value.sql(統計数値ファクト)
Silver 層で最も重要なのはファクトテーブルです。e-Stat の VALUE 配列を展開し、各観測値を1行にします。
-- dbt/models/silver/fact_estat_value.sql
{{ config(
materialized='incremental',
unique_key=['stats_data_id', 'area_code', 'time_code', 'category_code'],
partition_by={
'field': 'ingested_date',
'data_type': 'date'
},
cluster_by=['stats_data_id', 'area_code']
) }}
WITH raw_values AS (
SELECT
stats_data_id,
DATE(ingested_at) AS ingested_date,
-- BigQuery の JSON_QUERY_ARRAY で配列展開
value_row
FROM {{ source('bronze', 'estat_stats_data') }},
UNNEST(
JSON_QUERY_ARRAY(raw_json, '$.GET_STATS_DATA.STATISTICAL_DATA.DATA_INF.VALUE')
) AS value_row
{% if is_incremental() %}
WHERE DATE(ingested_at) > (SELECT MAX(ingested_date) FROM {{ this }})
{% endif %}
)
SELECT
stats_data_id,
JSON_VALUE(value_row, '$.@area') AS area_code,
JSON_VALUE(value_row, '$.@time') AS time_code,
JSON_VALUE(value_row, '$.@cat01') AS category_code,
SAFE_CAST(JSON_VALUE(value_row, '$."$"') AS FLOAT64) AS stat_value,
ingested_date
FROM raw_values
WHERE JSON_VALUE(value_row, '$."$"') IS NOT NULL
AND JSON_VALUE(value_row, '$."$"') != '-' -- e-Stat の欠損値表現schema.yml でデータ品質テストを定義
# dbt/models/silver/schema.yml
version: 2
models:
- name: fact_estat_value
description: "e-Stat 統計数値ファクトテーブル(silver 層)"
columns:
- name: stats_data_id
tests:
- not_null
- name: area_code
tests:
- not_null
- name: stat_value
tests:
- not_null
- dbt_utils.accepted_range:
min_value: 0dbt mart モデル(都道府県別人口推移)
Mart 層はビジネス課題に直結した集計テーブルを提供します。 Silver のファクト・ディメンションを JOIN して、プロダクトや BI ツールが使いやすい形に整形します。
dim_estat_area.sql(地域マスタ)
-- dbt/models/silver/dim_estat_area.sql
{{ config(materialized='table') }}
WITH area_meta AS (
SELECT DISTINCT
JSON_VALUE(class_obj, '$.@code') AS area_code,
JSON_VALUE(class_obj, '$.@name') AS area_name,
JSON_VALUE(class_obj, '$.@level') AS area_level,
DATE(ingested_at) AS ingested_date
FROM {{ source('bronze', 'estat_stats_data') }},
UNNEST(
JSON_QUERY_ARRAY(
raw_json,
'$.GET_STATS_DATA.STATISTICAL_DATA.CLASS_INF.CLASS_OBJ'
)
) AS class_obj_array,
UNNEST(
JSON_QUERY_ARRAY(class_obj_array, '$.CLASS')
) AS class_obj
WHERE JSON_VALUE(class_obj_array, '$.@name') = '地域'
)
SELECT
area_code,
area_name,
area_level,
-- 都道府県コード(2桁)を付与
CASE
WHEN LENGTH(area_code) = 5 THEN LEFT(area_code, 2)
ELSE area_code
END AS pref_code,
MAX(ingested_date) AS latest_ingested_date
FROM area_meta
WHERE area_code IS NOT NULL
GROUP BY 1, 2, 3, 4mart_population_prefecture_year.sql
-- dbt/models/mart/mart_population_prefecture_year.sql
{{ config(
materialized='table',
cluster_by=['area_code', 'year']
) }}
WITH population_fact AS (
SELECT
f.area_code,
-- e-Stat の time_code は "2020000000" 形式なので年を抽出
CAST(LEFT(f.time_code, 4) AS INT64) AS year,
f.stat_value AS population
FROM {{ ref('fact_estat_value') }} f
-- 国勢調査の stats_data_id を直接指定(または category_code でフィルタ)
WHERE f.category_code = '001' -- 総人口
AND f.stat_value IS NOT NULL
),
with_area AS (
SELECT
p.area_code,
d.area_name,
d.pref_code,
p.year,
p.population
FROM population_fact p
JOIN {{ ref('dim_estat_area') }} d
ON p.area_code = d.area_code
WHERE d.area_level = '2' -- 都道府県レベル
)
SELECT
pref_code,
area_code,
area_name,
year,
SUM(population) AS population
FROM with_area
GROUP BY 1, 2, 3, 4
ORDER BY year DESC, pref_codeプロダクト外部信号としての活用
このマートテーブルを BigQuery から直接クエリして、プロダクトの機能に組み込む例を示します。
# プロダクト API: 都道府県コードを受け取り人口推移を返す
from google.cloud import bigquery
def get_population_trend(pref_code: str, from_year: int = 2015) -> list[dict]:
"""都道府県コードに対応する人口推移を返す"""
client = bigquery.Client()
query = """
SELECT year, population
FROM `{project}.mart.mart_population_prefecture_year`
WHERE pref_code = @pref_code
AND year >= @from_year
ORDER BY year
"""
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("pref_code", "STRING", pref_code),
bigquery.ScalarQueryParameter("from_year", "INT64", from_year),
]
)
rows = client.query(query.format(project="your-project"), job_config=job_config)
return [{"year": row.year, "population": row.population} for row in rows]このような形で Mart テーブルをラップする API を作ると、フロントエンドやデータサイエンスチームが自由に利用できます。BigQuery の行レベルセキュリティと組み合わせることで、アクセス制御も細かく設定できます。
Cloud Run ingest エントリポイント
Cloud Run をインジェスト処理のエントリポイントにすることで、サーバーレスかつスケーラブルなパイプラインを構成できます。 Cloud Scheduler からの HTTP POST でトリガーし、Cloud Run がコレクターとローダーを呼び出す設計です。
Flask アプリ実装
# src/entrypoint.py
from __future__ import annotations
import logging
import os
from flask import Flask, Response, jsonify, request
from collectors.estat.client import EStatClient, EStatAPIError
from loaders.bigquery import BQLoader
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
app = Flask(__name__)
@app.route("/health", methods=["GET"])
def health() -> Response:
return jsonify({"status": "ok"})
@app.route("/ingest/stats-list", methods=["POST"])
def ingest_stats_list() -> Response:
"""統計表一覧を収集して bronze に書き込む"""
body = request.get_json(silent=True) or {}
keyword = body.get("keyword", "人口")
limit = int(body.get("limit", 100))
try:
client = EStatClient()
loader = BQLoader()
data = client.get_stats_list(search_word=keyword, limit=limit)
loader.insert_raw(
"estat_stats_list",
data,
extra_fields={"search_word": keyword},
)
return jsonify({"status": "ok", "keyword": keyword})
except EStatAPIError as exc:
logger.error("e-Stat API error: %s", exc)
return jsonify({"status": "error", "message": str(exc)}), 502
except Exception as exc:
logger.exception("Unexpected error: %s", exc)
return jsonify({"status": "error", "message": "internal error"}), 500
@app.route("/ingest/stats-data", methods=["POST"])
def ingest_stats_data() -> Response:
"""指定統計表のデータを収集して bronze に書き込む"""
body = request.get_json(silent=True) or {}
stats_data_id = body.get("statsDataId")
if not stats_data_id:
return jsonify({"status": "error", "message": "statsDataId is required"}), 400
try:
client = EStatClient()
loader = BQLoader()
data = client.get_stats_data(
stats_data_id=stats_data_id,
cd_area=body.get("cdArea"),
cd_time=body.get("cdTime"),
)
loader.insert_raw(
"estat_stats_data",
data,
extra_fields={"stats_data_id": stats_data_id},
)
return jsonify({"status": "ok", "stats_data_id": stats_data_id})
except EStatAPIError as exc:
logger.error("e-Stat API error: %s", exc)
return jsonify({"status": "error", "message": str(exc)}), 502
except Exception as exc:
logger.exception("Unexpected error: %s", exc)
return jsonify({"status": "error", "message": "internal error"}), 500
if __name__ == "__main__":
port = int(os.environ.get("PORT", 8080))
app.run(host="0.0.0.0", port=port, debug=False)Dockerfile
FROM python:3.12-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY src/ ./src/
ENV PYTHONPATH=/app/src
CMD ["gunicorn", "--bind", "0.0.0.0:8080", "--workers", "2", "entrypoint:app"]Cloud Scheduler 設定(Terraform)
# infra/terraform/scheduler.tf
resource "google_cloud_scheduler_job" "ingest_population" {
name = "estat-ingest-population"
schedule = "0 3 * * 1" # 毎週月曜 3:00 JST
time_zone = "Asia/Tokyo"
http_target {
uri = "${google_cloud_run_service.ingest.status[0].url}/ingest/stats-list"
http_method = "POST"
body = base64encode(jsonencode({ keyword = "人口", limit = 100 }))
oidc_token {
service_account_email = google_service_account.scheduler.email
}
}
}運用上の注意点
実本番環境で安定稼働させるために把握しておくべき注意点をまとめます。
e-Stat API のレートリミット
e-Stat の利用規約では「過度なアクセスを避けること」と定めています。実装上の推奨は以下のとおりです。
| 項目 | 推奨値 | 理由 |
|---|---|---|
| リクエスト間隔 | 1秒以上 | サーバー負荷軽減 |
| 同時並列リクエスト | 1(直列) | レートリミット回避 |
| バッチ実行時間帯 | 深夜〜早朝 | ピーク時間を避ける |
limit パラメータ | 最大10,000 | 1リクエストの取得上限 |
統計表によってはデータ件数が10,000件を超える場合があります。その際は startPosition パラメータを使ってページングしてください。
認証情報の管理
# .env(必ず .gitignore に追加)
ESTAT_APP_ID=your_app_id_here
GOOGLE_CLOUD_PROJECT=your-project-id
# .gitignore
.env
.env.local
credentials/Cloud Run にシークレットを渡す際は、直接環境変数に書かず Secret Manager を使います。
# Secret Manager に登録
gcloud secrets create estat-app-id --data-file=- <<< "YOUR_APP_ID"
# Cloud Run にシークレットをマウント
gcloud run services update estat-ingest \
--set-secrets "ESTAT_APP_ID=estat-app-id:latest"段階的な開発フロー
Step 1: DuckDB で探索
↓ 使えそうなデータセットを特定
Step 2: Python クライアントで小規模取得
↓ 1〜2個の統計表を試す
Step 3: bronze への蓄積(ローカル BigQuery Emulator)
↓ スキーマを確認
Step 4: dbt silver を手動実行
↓ データ品質テストをパス
Step 5: Cloud Run + Scheduler で定期実行
↓ 本番安定稼働DuckDB 探索をスキップして最初から Cloud Run で書くと、「このデータは使えない」と分かった時点でパイプライン全体を作り直す羽目になります。探索フェーズに1〜2時間かけておくと、実装フェーズの手戻りを大幅に減らせます。
dbt でのデータ品質管理
# dbt/models/mart/schema.yml
version: 2
models:
- name: mart_population_prefecture_year
description: "都道府県別・年次人口マートテーブル"
columns:
- name: pref_code
tests:
- not_null
- relationships:
to: ref('dim_estat_area')
field: pref_code
- name: year
tests:
- not_null
- dbt_utils.accepted_range:
min_value: 1980
max_value: 2030
- name: population
tests:
- not_null
- dbt_utils.accepted_range:
min_value: 0dbt のテストを CI に組み込み、dbt test が失敗したら Mart テーブルを更新しない設計にしておくと、BI ツールに壊れたデータが流れることを防げます。
まとめと今後の展開
本記事では、e-Stat API をデータ基盤に取り込む一連の流れを解説しました。各フェーズのポイントを振り返ります。
| フェーズ | ツール | 主な成果物 |
|---|---|---|
| 探索 | DuckDB | 使えるデータセットの特定 |
| 収集 | Python + Cloud Run | bronze テーブルへの生JSON蓄積 |
| 変換 | dbt (silver) | 型安全・正規化済みの dim/fact テーブル |
| 集計 | dbt (mart) | プロダクト・BI 向けの集計テーブル |
| 提供 | BigQuery API | 外部信号 API・BI 接続 |
次のステップ
Mart の拡充として、都道府県別人口以外にも以下のマートテーブルを追加することが考えられます。
mart_employment_industry_year(産業別就業者数)mart_birth_rate_prefecture_year(都道府県別出生率)mart_household_income_distribution(所帯収入分布)
他省庁APIへの横展開も重要な次のステップです。国土交通省の不動産取引価格情報 API、厚生労働省の求人倍率データなど、同様のパターンで取り込めるデータソースが複数あります。EStatClient のクラス構造を継承・拡張することで、新しいデータソースのクライアントをスムーズに追加できます。
# 横展開の例: 国交省 不動産取引価格 API
class MLITClient(BaseGovDataClient):
BASE_URL = "https://www.land.mlit.go.jp/webland/api"
# EStatClient と共通のリトライ・ロギング機構を継承このパターンの本質は「探索と本番を分離する」ことです。DuckDB という使い捨ての探索環境を持つことで、本番パイプラインを汚染せずに新しいデータソースを試せます。外部データを躊躇なく試し、価値があると分かったものだけを本番に昇格させる文化が、データ活用を加速させます。
政府統計データは整備されたデータの宝庫であり、多くの企業でまだ活用されていない競争優位の源泉です。本記事のアーキテクチャを出発点に、自社プロダクトに合わせた外部信号データ基盤を構築してみてください。
関連記事
- e-Stat API Python クライアントの設計と実装 — 本記事で使用した Python クライアントの詳細設計・テスト戦略を解説
- AI Ready データ基盤とオントロジー — データ基盤に「意味のネットワーク」を加え、AI が正しくデータを理解できる状態を作る方法