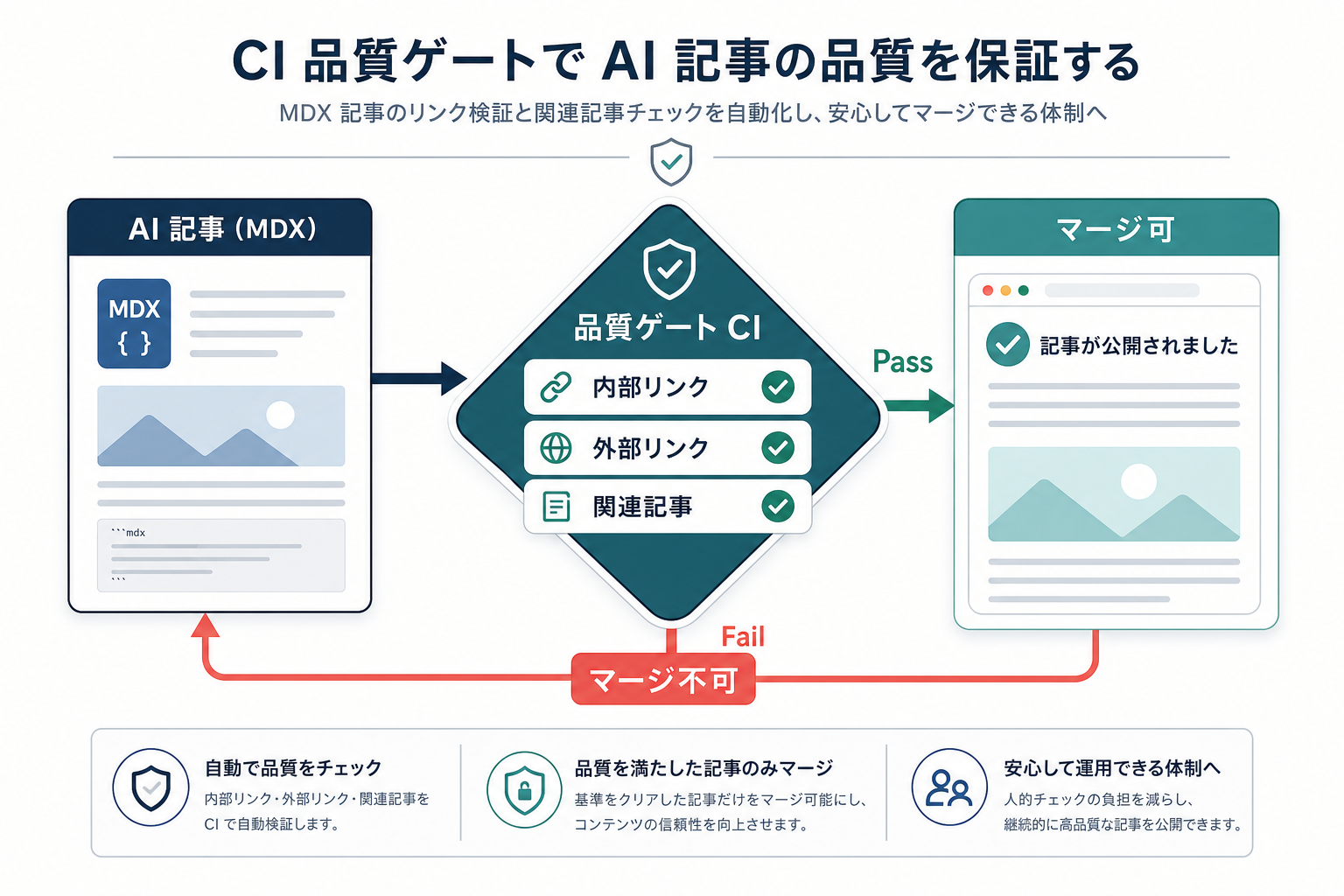
AI生成ブログの品質ゲートを GitHub Actions で機械検証する
LLM に記事を書かせる運用を回し始めると、「評価プロンプトでは合格したのに、公開後に見返すと内部リンクが0本で回遊が死んでいる」 事故に必ず一度はぶつかります。この記事では、AI による記事生成パイプラインを運用しているデータアナリスト・データエンジニアが、MDX 形式の記事を 機械的にチェックして CI でマージをブロックする品質ゲート を導入する手順を、Node.js スクリプトと GitHub Actions の具体例つきで解説します。読み終えたら、自分のプロジェクトの apps/site/src/content/blog/ 相当のディレクトリに同じゲートを仕込めるようになります。
AI生成記事の自己チェックだけでは品質が担保できない理由
LLM に「内部リンクを2本以上入れてください」と指示しても、生成結果にリンクが0本で返ってくることがあります。評価用プロンプト(AI 自身に記事を採点させる仕組み)を組んでも、採点 AI が「はい、要件を満たしています」と嘘をつく場面は現実に起きます。
この現象の厄介さは、人間がレビューで見逃したときに露呈することです。事実、筆者のプロジェクトでも ## 関連記事 セクションが無い記事、外部公式ドキュメントへの参照がゼロの記事が複数公開され、記事間の回遊率と SEO の両方に悪影響を出しました。
対策としては、AI の主観的チェックに依存せず、機械的に数えられる指標で CI の合否を決める のが最も堅実です。採点 AI は「なぜその構成にしたか」を判断するのには向いていますが、「リンクが 2 本あるか」は正規表現で数えた方が早く、嘘もつきません。
機械検証すべきチェック項目の設計
記事タイプごとに最低ラインを決めます。筆者のプロジェクトでは 2 種類の記事タイプを扱っているので、それぞれに閾値を持たせます。
| チェック項目 | tech-article | dev-log | 備考 |
|---|---|---|---|
内部リンク(/blog/ 配下) | 2 本以上 | 1 本以上 | 回遊導線の最低保証 |
外部参照リンク(https://) | 2 本以上 | 1 本以上 | 一次情報への導線 |
## 関連記事 セクション | 必須 | 必須 | 関連記事ブロックの明示 |
draft: true | 検査スキップ | 検査スキップ | 下書きは対象外 |
「記事タイプ」は MDX のフロントマターから取得します。Astro のコンテンツコレクションは Zod スキーマで category や tags をバリデートしてくれますが、リンク数の検証までは面倒を見てくれません。Zod の役割はあくまで構造バリデーションで、本文の内容検査は別の層で組む必要があります(Content Collections の責務範囲は Astro 公式ドキュメント を参照)。
なぜこの4項目に絞るか
検査項目はむやみに増やさないのが鉄則です。チェックが増えると、AI が「チェックを通すためだけのダミーリンク」を差し込む という別種のハックが始まります。リンク数の下限と「関連記事セクションの存在」に絞ることで、AI が意味のあるリンクを選ぶインセンティブを残せます。
Node.js スクリプトでMDX記事の品質を機械検証する手順
既存の CI が bash ベースでも、このチェックは Node.js 単体で書くと MDX のフロントマター解析が楽になります。フロントマター解析には gray-matter を使います。Astro、VitePress、Gatsby など主要な SSG が採用している事実上の標準ライブラリです。
1. フロントマターと本文を分離する
// .github/scripts/check-blog-quality.mjs
import { readFileSync, readdirSync } from 'node:fs';
import { join } from 'node:path';
import matter from 'gray-matter';
const BLOG_DIR = 'apps/site/src/content/blog';
const THRESHOLDS = {
'tech-article': { internal: 2, external: 2 },
'dev-log': { internal: 1, external: 1 },
};THRESHOLDS は記事タイプごとの下限を1か所に集約しておきます。ここを変えるだけで既存記事の再検査ができる状態にしておくと、運用途中で基準を引き上げても慌てずに済みます。
2. リンク数を正規表現で数える
MDX は JSX 記法も混ざりますが、リンク検出は Markdown 記法 [text](url) だけで十分です。JSX で書かれたリンクは稀ですし、検出漏れは「リンク不足」として検出される側なのでフェイルセーフに倒れます。
const INTERNAL_LINK_RE = /\]\((\/blog\/[^)]+)\)/g;
const EXTERNAL_LINK_RE = /\]\((https?:\/\/[^)]+)\)/g;
function countLinks(content) {
return {
internal: [...content.matchAll(INTERNAL_LINK_RE)].length,
external: [...content.matchAll(EXTERNAL_LINK_RE)].length,
};
}3. 1ファイルずつ検査する
function checkFile(path) {
const raw = readFileSync(path, 'utf8');
const { data: fm, content } = matter(raw);
if (fm.draft === true) return { path, status: 'skip' };
const type = fm.category === 'dev-log' ? 'dev-log' : 'tech-article';
const threshold = THRESHOLDS[type];
const counts = countLinks(content);
const hasRelatedSection = /^##\s+関連記事\s*$/m.test(content);
const errors = [];
if (counts.internal < threshold.internal)
errors.push(`内部リンク不足: ${counts.internal}/${threshold.internal}`);
if (counts.external < threshold.external)
errors.push(`外部リンク不足: ${counts.external}/${threshold.external}`);
if (!hasRelatedSection)
errors.push('`## 関連記事` セクションが見つかりません');
return { path, type, errors };
}
const results = readdirSync(BLOG_DIR)
.filter((f) => f.endsWith('.mdx'))
.map((f) => checkFile(join(BLOG_DIR, f)));
const failed = results.filter((r) => r.errors?.length);
if (failed.length) {
for (const r of failed) {
console.error(`\n[FAIL] ${r.path} (${r.type})`);
for (const e of r.errors) console.error(` - ${e}`);
}
process.exit(1);
}
console.log(`OK: ${results.length} 記事すべて品質基準を満たしています`);このスクリプトは MDX 記事の記事タイプを category フィールドから読み、閾値比較と関連記事セクションの有無を一括で判定します。違反があれば process.exit(1) で非 0 終了し、CI ジョブを落とします。
外部リンクの死活まで見るか
「リンクの本数」ではなく「リンクが実際に 200 を返すか」まで見たい場合は、markdown-link-check を別ジョブで足します。ただし外部サイトの一時的な 503 で CI が落ちる副作用があるため、必須チェックではなく警告扱い にするのが現実的な落とし所です。
GitHub Actions のCIとマージゲートへのチェックの組み込み方
生成した記事の PR で必ずこのチェックを走らせるため、2 か所に組み込みます。
1. 通常の CI ワークフロー
記事変更が含まれる PR で機械チェックを実行します。paths フィルタで記事ディレクトリの変更時だけ走らせると、他の PR の CI を遅らせずに済みます(トリガーの書き方は GitHub Actions ワークフロー構文 を参照)。
# .github/workflows/ci.yml(抜粋)
on:
pull_request:
paths:
- 'apps/site/src/content/blog/**'
- '.github/scripts/check-blog-quality.mjs'
jobs:
blog-quality:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: '20'
- run: pnpm install --frozen-lockfile
- run: node .github/scripts/check-blog-quality.mjs2. 記事 PR の自動マージワークフロー
AI 生成 PR を自動マージするパイプライン(例: auto-merge-blog-pr.yml)にも同じチェックを挟みます。こちらが最重要です。通常 CI でブロックできても、自動マージのジョブが別ルートで PR をマージできてしまうと意味がありません。
- name: Blog quality gate
run: node .github/scripts/check-blog-quality.mjs
# このステップが失敗すると後続のマージステップに進まない既存の記事自動生成パイプライン全体の構成と、この品質ゲートが差し込まれる位置関係は generate-blog を PR作成止まりから公開完了まで自動化した実装ログ と対応します。
導入効果と運用上の注意点
品質ゲートを入れると、AI が書いた記事のうち約1〜2割が初回でブロックされる想定です。これは「AI の自己チェックをどの程度信用していたか」を測る健康診断にもなります。ブロック率が高止まりする場合は、生成プロンプトに埋め込んだ「関連記事2本、外部リンク2本」の指示が読まれていない証拠なので、プロンプトの構造を見直すシグナルとして使えます。
運用上の注意は次の3点です。
- 既存記事の再検査を忘れない: ゲート導入時点で既存記事に違反があれば、まずそちらを先に修正するか猶予期間を設ける
- 閾値を上げすぎない: 下限は「記事として成立する最低ライン」を担保するもの。質の追求は採点 AI とレビュアーに任せる
- レンダラ依存の記法を避ける: 箇条書きが壊れる問題など、本文ではなく CSS やレンダラ側の問題でゲートを通過/落下するのは別レイヤーで扱う。サイトコンセプトと記事生成プロンプトの整合に関する周辺の設計は ブログ記事生成フローのコンセプト統合 を参照
まとめ
AI にコンテンツを書かせるパイプラインでは、主観的な評価 AI と、機械的な CI チェックを両輪で持つ のが現実的な品質運用です。主観判断は AI に任せ、数えられる指標は grep と正規表現で機械化する。この切り分けが、運用コストを上げずに品質事故を防ぐ最短ルートになります。紹介したスクリプトは .github/scripts/ に1ファイル置くだけで動くサイズなので、まずはリンク数のみの最小構成で導入し、運用データを見ながら項目を足していくのをおすすめします。
関連記事
- generate-blog を PR作成止まりから公開完了まで自動化した実装ログ — このゲートを差し込む土台となる自動化パイプラインの全体像
- ブログ記事生成フローのコンセプト統合:ハーネス強化による一貫性確保 — AI 記事生成プロンプト側にコンセプトと品質要件を組み込む前段の設計
- プロンプトファイル構造統一による保守性向上:evaluator prompt の独立化実践 — 採点 AI 側の評価基準をファイル分離して保守性を上げる実践